A machine learning app that enables the Hopscotch Project Curators to review 2700 projects per week.
One of the most difficult parts of any user content platform is selecting which content to feature. Hopscotch is no exception to this with picking the most fun and interesting coding projects made by kids. Without the ability to query the database directly, the only way to bulk-assess a project’s quality was by its metadata, that is, its view statistics, creation time, draft age, and so on.
As a part of my original Hopscotch Tools project, I added a feature to filter projects based on a predefined set of criteria. This was fairly effective at finding a few interesting projects (by filtering out spam). However, the challenge of scoring thousands of projects accurately without looking at its code still remained.
So, I turned to machine learning in May 2024 as a next step.
I began by evaluating what machine learning model would suit this task best. I needed the model to output a score based on various combinations of features, with some features expected to be significantly more important than others. I chose to use a Random Forest Regressor because of its ability to create partitions and identify feature importance.
After experimenting with the model, I was able to effectively separate the data and capture complex patterns in the projects’ metadata. Ultimately, the model was able to account for 94% the variability in score for projects over a 6-month period.
In addition to creating the model, I used Streamlit to create a playground for testing the model against new data and also built a custom interface that allowed other team members to add their own votes to projects! My custom interface is built with React and uses PostgreSQL to store the curation team’s votes, enabling secondary review of potential featured projects for the first time.
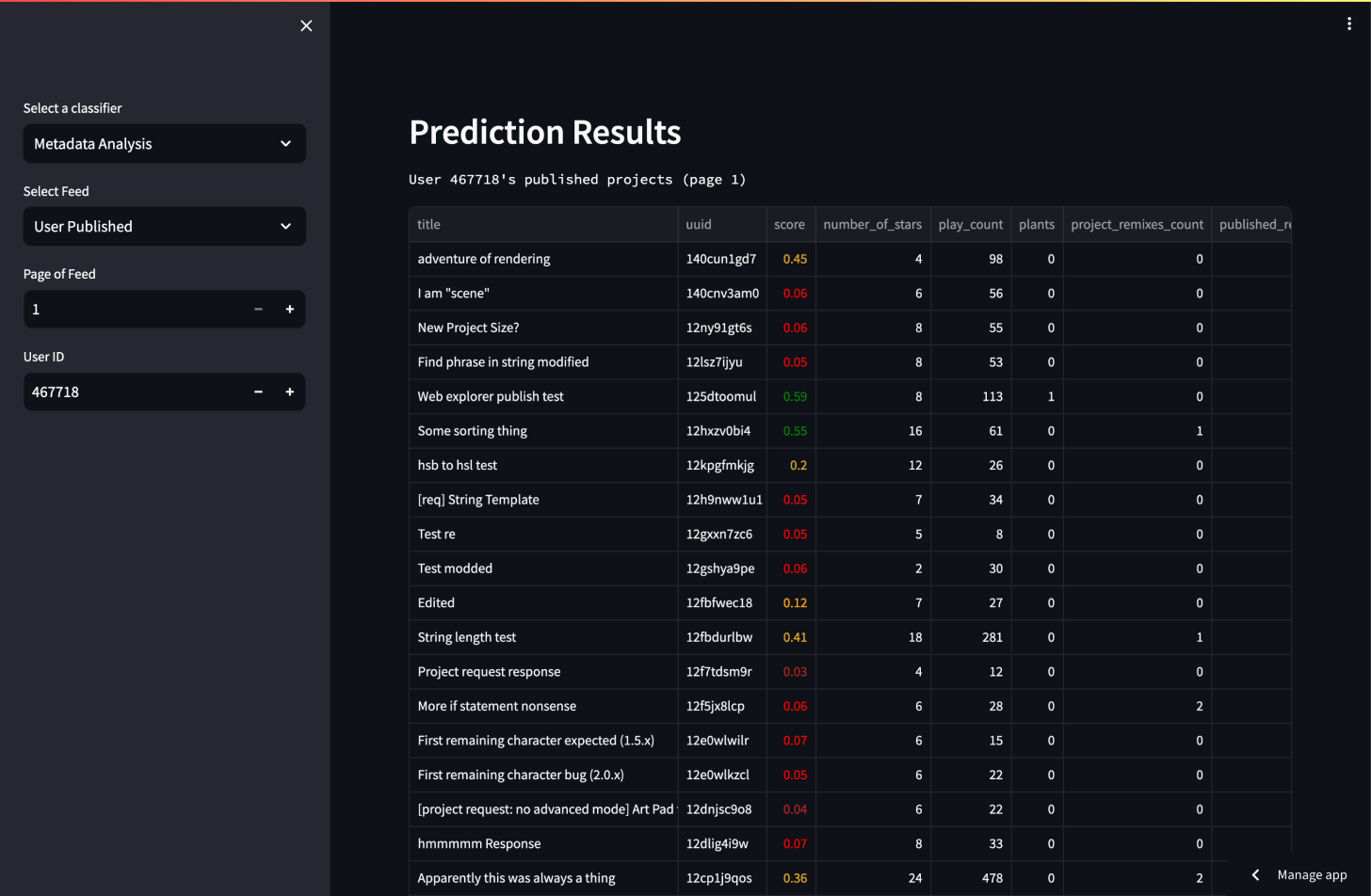
The Streamlit playground showing score and metadata stats
What started as a fun project to start learning how to train ML models turned out to have a far-reaching impact. To start, the model’s ability to account for 94% of variability between project metadata and quality gave us confidence that a majority of the scores would be representative of the actual data.
But the true power came when I paired the ML model with a user-friendly front end. Being able to browse through the newest project feed with the ML model directly accessible enabled the curation team to spend 7x less time filtering through projects in a single session.
In addition to the time saved, we were able to significantly increase the number of projects we were actually able to feature. With HopKeep, the curation team is able to review over 2700 projects every week, and despite this, we are able to feature 5.2x as many projects compared to manually looking for potential projects to feature with the static criteria filter used previously.
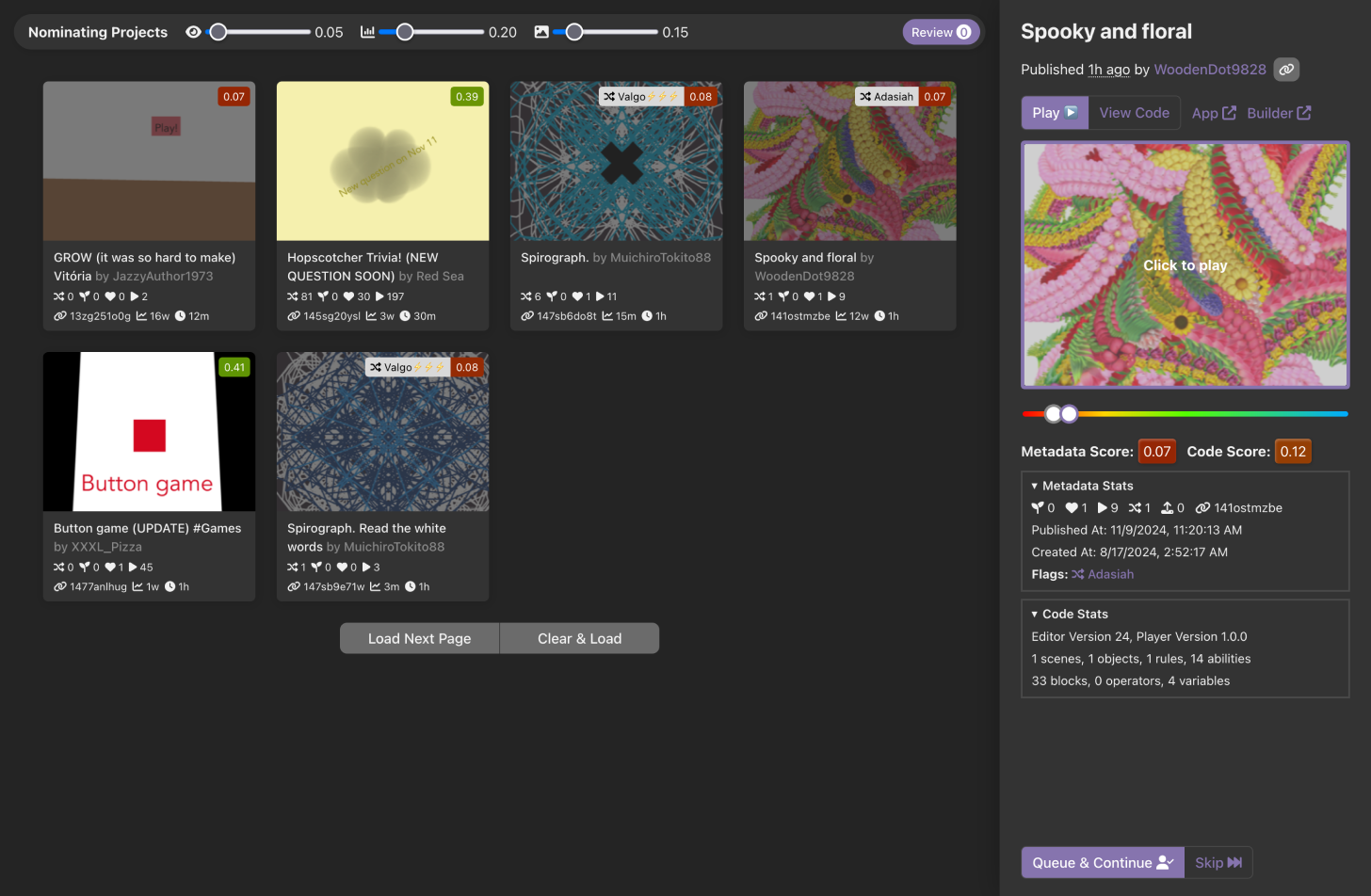
The curation interface showing the metadata and code scores of recent projects